 NTSEBench: Cognitive Reasoning Benchmark for Vision Language Models
NTSEBench: Cognitive Reasoning Benchmark for Vision Language Models
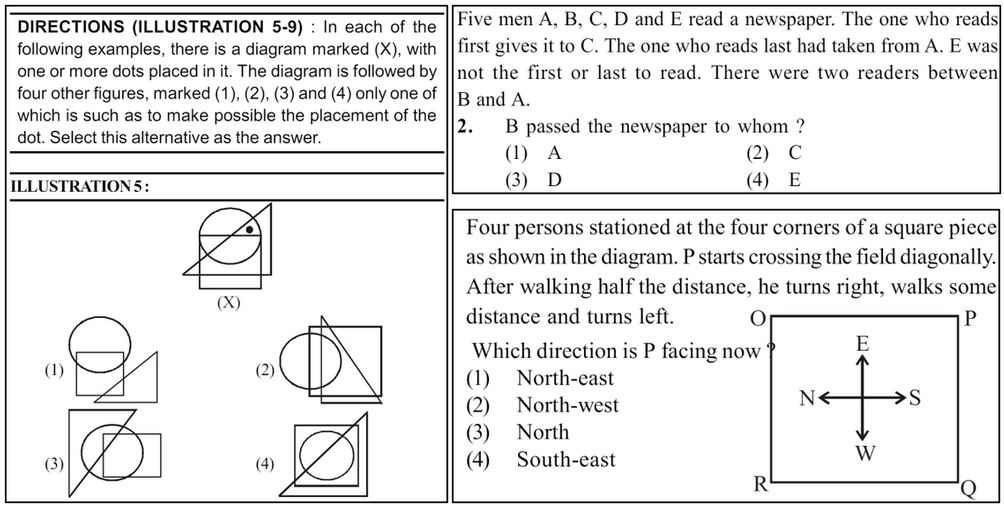
Examples from the NTSEBench dataset
Three samples of textual, direction, and spatial reasoning questions from the proposed dataset. Solutions to these questions are not included here but are provided in the dataset
NTSEBench
dataset
Cognitive textual and visual reasoning tasks, including puzzles, series, and analogies, demand the ability to quickly reason, decipher, and evaluate patterns both textually and spatially. Due to extensive training on vast amounts of human-curated data, large language models (LLMs) and vision language models (VLMs) excel in common-sense reasoning tasks, but still struggle with more complex reasoning that demands deeper cognitive understanding. We introduce NTSEBench, a new dataset designed to evaluate cognitive multimodal reasoning and problem-solving skills of large models. The dataset contains 2,728 multiple-choice questions, accompanied by a total of 4,642 images, categorized into 26 different types. These questions are drawn from the nationwide NTSE examination in India and feature a mix of visual and textual general aptitude challenges, designed to assess intelligence and critical thinking skills beyond mere rote learning. We establish baselines on the dataset using state-of-the-art LLMs and VLMs. To facilitate a comparison between open-source and propriety models, we propose four distinct modeling strategies to handle different modalities—text and images—in the dataset instances.
NTSEBench Dataset
The National Talent Search Examination (NTSE), administered by the National Council of Educational Research and Training (NCERT) in India since 1963, is a nationwide exam for secondary-grade students. The exam consists of two sections designed to assess a wide range of analytical skills: the Mental Ability Test (MAT) and the Scholastic Aptitude Test (SAT). The MAT section evaluates students’ general aptitude, critical thinking, logical and spatial reasoning, and analytical problem-solving skills (for both textual and visual problems). In contrast, the SAT assesses their domain-specific knowledge in science and mathematics. All questions in the NTSE are multiplechoice (MCQ) with one correct option. Questions and options can be text/image or a combination of both, i.e., multi-modal. We aim to create a dataset focused on cognitive reasoning abilities (MAT-type questions). Cognitive Reasoning. Cognitive understanding in the context of NTSEBench refers to the ability to process information, recognize patterns, draw inferences, and solve problems using critical, logical and analytical reasoning. This aligns with fundamental concepts in cognitive science, such as problem-solving, pattern recognition, and inferential reasoning
| Categories | # Samples | Categories | # Samples |
|---|---|---|---|
| Series | 256 | Non-Verbal Series | 95 |
| Alphabet Test | 94 | Missing Character | 127 |
| Odd one out | 170 | Embedded Figure | 96 |
| Analogy | 151 | Non-Verbal odd one out | 70 |
| Coding-Decoding | 149 | Non-Verbal Analogy | 100 |
| Number and Ranking | 139 | Paper Folding & Cutting | 96 |
| Blood Relation | 126 | Incomplete Figure | 94 |
| Mathematical Operations | 99 | Figure Partition | 71 |
| Puzzle Test | 95 | Cube and Dice | 23 |
| Syllogisms | 44 | Dot problem | 23 |
| Statement & Conclusions | 143 | Direction Sense | 36 |
| Data Sufficiency | 90 | Time and Clock | 51 |
| Mirror, Water and Images | 50 | ||
| Venn diagrams | 111 |
Strategies Proposed for analysis
Evaluating the reasoning abilities of large language models (LLMs) with text-based questions is straightforward. For vision-language models (VLMs), reasoning with vision-text questions is generally straightforward. Some API access model models, like GPT-4o and Gemini, support multi-image inputs, while many others do not (open-source models like LLaVA-OneVision and Ovis are emerging with this capability). To address these task-specific and input-related dependencies, we propose four strategies to fairly evaluate the reasoning abilities of both open-source and API-based models.
For instances where question type(J) or questions(Q),options(O) and solutions(S) is text(T),we use a standard text-based QA model like GPT3.5-Turbo or Llama3-70b
We propose a modeling approach where questions and all the options are presented to the model as a single image. This image consolidates all relevant textual and visual content exactly as it appears in the examination paper, effectively capturing the entire question, including both textual and visuals. This strategy utilizes the OCR capabilities of VLM models to interpret and analyze the content, enabling them to process both text and visual elements within the same input.
In this approach, we integrate text with multiple images to create an interwoven context. This method involves placing related textual and visual elements in proximity, enhancing the model’s ability to draw connections between them.
Open-source models typically lack the capability to integrate text and images within a single prompt. To enable fair comparisons, we propose an alternative modeling strategy where the question and option images are combined into a single composite image, labeled as Figure 1, Figure 2, etc. This composite image is accompanied by a structured textual prompt that describes different parts of the image, directing the model’s attention to relevant visual details. The composite image and prompt are then used to evaluate the model’s performance, testing its ability to interpret and respond to questions based on the integrated visual and textual information.
Experiment ResultsThe Analysis section of the paper presents a comprehensive evaluation of the impact of various strategies on the NTSEBench dataset. The findings indicate that
| SER | ALP | ODO | ANA | COD | NUM | BLR | MTO | PUZ | SYL | STC | DAT | Avg. Per | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Image Only - Zero Shot | ||||||||||||||
| CogVLM-2 | 14.84 | 17.02 | 20.00 | 19.87 | 24.83 | 16.55 | 23.81 | 20.20 | 20.00 | 22.73 | 22.12 | 15.56 | 19.79 | |
| InternLM-XComposer2 | 18.36 | 18.09 | 21.65 | 19.95 | 17.42 | 11.51 | 15.87 | 24.24 | 25.26 | 31.16 | 17.31 | 8.89 | 17.22 | |
| Qwen-VL-Chat | 29.69 | 23.44 | 29.44 | 45.45 | 39.29 | 17.97 | 22.11 | 45.36 | 46.97 | 45.38 | 34.25 | 34.18 | 33.73 | |
| Gemini 1.5 Pro | 32.42 | 31.91 | 47.64 | 52.32 | 52.37 | 37.41 | 47.29 | 49.29 | 47.37 | 47.13 | 38.46 | 44.44 | 39.55 | |
| GPT-4o | 28.12 | 31.91 | 41.94 | 50.03 | 37.14 | 52.38 | 34.34 | 46.34 | 53.85 | 43.85 | 35.38 | 38.17 | 36.17 | |
| Image Only - Few Shot | ||||||||||||||
| Gemini 1.5 Pro | 23.32 | 23.08 | 46.11 | 47.97 | 24.66 | 36.76 | 36.59 | 32.29 | 42.94 | 31.71 | 32.67 | 22.99 | 33.37 | |
| GPT-4o | 32.02 | 29.67 | 50.30 | 40.42 | 32.19 | 35.29 | 43.09 | 25.00 | 46.74 | 41.46 | 53.47 | 34.48 | 38.85 | |
| Standard QA - Zero Shot | ||||||||||||||
| Mixtral-8x7B | 19.76 | 19.57 | 24.71 | 45.52 | 14.77 | 26.09 | 29.37 | 29.59 | 32.93 | 24.32 | 53.85 | 33.33 | 29.48 | |
| Llama-3 70B | 35.18 | 26.09 | 47.65 | 57.93 | 36.36 | 36.23 | 50.79 | 31.63 | 60.98 | 54.05 | 52.88 | 40.48 | 44.18 | |
| GPT-3.5 Turbo | 35.97 | 32.61 | 40.00 | 51.72 | 36.36 | 25.36 | 36.51 | 27.55 | 46.34 | 35.14 | 40.38 | 32.14 | 36.67 | |
| CogVLM-2 | 22.27 | 21.28 | 27.65 | 34.44 | 22.82 | 18.71 | 30.95 | 19.19 | 29.47 | 18.18 | 28.85 | 27.78 | 25.13 | |
| InternLM-XComposer2 | 21.88 | 24.47 | 19.41 | 36.42 | 25.50 | 28.78 | 25.40 | 27.27 | 45.26 | 40.91 | 34.62 | 28.89 | 29.90 | |
| Qwen-VL-Chat | 30.08 | 18.09 | 23.53 | 31.13 | 26.85 | 15.11 | 24.60 | 27.27 | 28.26 | 13.64 | 15.38 | 24.44 | 23.19 | |
| Gemini 1.5 Pro | 63.67 | 39.36 | 60.00 | 69.54 | 61.07 | 68.35 | 58.73 | 45.45 | 81.05 | 65.91 | 70.19 | 63.33 | 62.22 | |
| GPT-4o | 42.58 | 35.11 | 55.88 | 65.56 | 38.26 | 42.45 | 68.25 | 41.41 | 69.47 | 63.64 | 70.19 | 43.33 | 53.01 | |
| LLaVA-OneVision | 42.19 | 32.98 | 50.59 | 57.62 | 45.64 | 36.69 | 57.94 | 37.37 | 64.21 | 50.00 | 62.50 | 46.67 | 48.70 | |
| Ovis1.6-Gemma2-9B | 42.58 | 31.91 | 50.00 | 50.99 | 42.95 | 46.04 | 38.89 | 31.31 | 53.26 | 27.27 | 55.77 | 33.33 | 42.03 | |
| Standard QA - Few Shot | ||||||||||||||
| Mixtral-8x7B | 27.20 | 24.72 | 28.14 | 50.70 | 29.41 | 27.41 | 33.33 | 29.47 | 18.99 | # | 55.45 | 32.10 | 32.44 | |
| Llama-3 70B | 34.00 | 16.85 | 44.91 | 51.41 | 36.47 | 34.81 | 39.84 | 32.63 | 34.18 | # | 50.50 | 34.57 | 37.28 | |
| GPT-3.5 Turbo | 30.80 | 32.58 | 20.96 | 47.89 | 30.59 | 31.11 | 30.08 | 29.47 | 36.71 | # | 40.59 | 34.57 | 33.21 | |
| Gemini 1.5 Pro | 63.24 | 37.36 | 59.28 | 68.92 | 60.27 | 68.38 | 58.54 | 43.75 | 80.43 | 63.41 | 70.30 | 62.07 | 61.32 | |
| GPT-4o | 42.29 | 40.66 | 58.08 | 67.57 | 44.52 | 40.44 | 69.92 | 46.88 | 72.83 | 63.41 | 71.29 | * | 56.17 | |
| Advanced Reasoning Models | ||||||||||||||
| OpenAI o1-preview | 80.62 | 90.22 | 84.05 | 73.13 | 85 | 85.83 | 83.61 | 83.7 | 84.81 | 81.08 | 72.28 | 83.33 | 81.88 | |
Zero-shot and Few-shot performance of different models across various text-only categories. We report results using two different modelling strategies Image Only and Standard QA.
italics font for propriety models, i.e., money or API access is required to run these models. The # is due to the category’s solution contains images thus restricting few shot on text-only models.
Note: (* )In some models, a common issue arises when a model refrains from providing a response due to safety concerns, often stemming from misinterpretation of the image’s intent
| Qwen-VL-Chat | 28.12 | 19.82 | 19.61 | 12.6 | 22.11 | 27.14 | 22.00 | 23.40 | 27.17 | 15.73 | 23.96 | 30.21 | 8.45 | 17.39 | 21.26 |
| Gemini 1.5 Pro | 63.54 | 64.86 | 70.59 | 37.01 | 33.68 | 25.71 | 32.00 | 38.30 | 35.87 | 43.82 | 30.21 | 36.46 | 46.48 | 30.43 | 42.06 |
| GPT-4o | 37.50 | 50.45 | 41.18 | 29.92 | 16.84 | 22.86 | 26.00 | 23.40 | 34.78 | 35.96 | 27.08 | 22.92 | 45.07 | 17.39 | 30.81 |
| LLaVA-OneVision | 27.27 | 39.64 | 44.44 | 32.00 | 14.74 | 28.57 | 26.00 | 26.60 | 32.61 | 36.59 | 26.04 | 37.50 | 33.80 | 26.09 | 30.85 |
| Ovis1.6-Gemma2-9B | 35.42 | 36.04 | 39.22 | 23.62 | 25.26 | 28.57 | 19.00 | 32.98 | 32.61 | 10.11 | 29.17 | 23.96 | 9.86 | 21.74 | 26.25 |
| Gemini 1.5 Pro | 62.37 | 63.89 | 68.75 | 36.29 | 31.52 | 23.88 | 29.9 | 36.26 | 33.71 | 41.86 | 27.96 | 34.41 | 44.12 | 20 | 39.63 |
| GPT-4o | 39.78 | 52.78 | 52.08 | 27.42 | 17.39 | * | * | 19.78 | * | 38.37 | 33.33 | * | 41.18 | * | 35.79 |
| CogVLM-2 | 18.75 | 18.02 | 25.49 | 14.96 | 18.95 | 20 | 8.00 | 12.77 | 7.61 | 19.10 | 16.67 | 12.50 | 12.68 | 4.35 | 14.98 |
| Qwen-VL-Chat | 21.05 | 26.13 | 27.45 | 22.22 | 26.32 | 21.43 | 17.00 | 21.28 | 19.57 | 25.84 | 25 | 18.75 | 18.31 | 17.39 | 21.98 |
| InternLM-XComposer2 | 20.83 | 20.72 | 15.69 | 17.32 | 15.79 | 11.43 | 10.00 | 14.89 | 8.70 | 19.10 | 10.42 | 11.46 | 22.54 | 8.70 | 14.82 |
| Gemini 1.5 Pro | 52.08 | 37.84 | 49.02 | 25.20 | 24.21 | 24.29 | 27 | 26.6 | 29.35 | 32.58 | 23.96 | 23.96 | 42.25 | 34.78 | 32.36 |
| GPT-4o | 40.62 | 31.53 | 33.33 | 22.05 | 22.11 | 25.71 | 19 | 24.47 | 23.91 | 26.97 | 34.38 | 23.96 | 42.25 | 21.74 | 28.00 |
| CogVLM-2 | 15.62 | 12.61 | 29.41 | 11.02 | 8.42 | 4.29 | 6 | 3.19 | 11.96 | 15.73 | 9.38 | 10.42 | 8.45 | 17.39 | 11.70 |
| Qwen-VL-Chat | 21.88 | 18.92 | 27.45 | 5.51 | 23.16 | 22.86 | 20 | 24.47 | 26.09 | 8.99 | 20.83 | 19.79 | 8.45 | 8.7 | 18.36 |
| InternLM-XComposer2 | 25 | 20.72 | 25.49 | 17.32 | 18.95 | 8.57 | 15 | 5.32 | 16.3 | 12.36 | 20.83 | 10.42 | 12.68 | 13.04 | 15.85 |
| Gemini 1.5 Pro | 54.17 | 49.55 | 62.75 | 37.8 | 24.21 | 24.29 | 21 | 29.79 | 21.74 | 46.07 | 23.96 | 23.96 | 40.85 | 26.09 | 34.73 |
| GPT-4o | 50 | 45.95 | 39.22 | 28.35 | 32.63 | 25.71 | 26 | 18.09 | 22.83 | 40.45 | 23.96 | 28.12 | 40.85 | 26.09 | 32.01 |
| Gemini 1.5 Pro | 61.29 | 47.22 | 68.75 | 32.26 | 17.39 | 16.42 | 18.56 | 27.47 | 20.22 | 44.19 | 20.43 | 25.81 | 44.12 | 25 | 33.50 |
| GPT-4o | 41.94 | 49.07 | 45.83 | 27.42 | 15.22 | 23.88 | 22.68 | 15.38 | 25.84 | 34.88 | 26.88 | 22.58 | 35.29 | 25 | 29.42 |
Zero-shot and Few-shot performance of different models across various Text+Vision categories. We report results using 3 different modelling strategies i.e. Interleaved,Image-Only and StandardVQA.
italics font for propriety models, i.e., money or API access is required to run these models. The # is due to the category’s solution contains images thus restricting few shot on text-only models.
Note: (* )In some models, a common issue arises when a model refrains from providing a response due to safety concerns, often stemming from misinterpretation of the image’s intent.
@misc{pandya2025ntsebenchcognitivereasoningbenchmark,
title={NTSEBENCH: Cognitive Reasoning Benchmark for Vision Language Models},
author={Pranshu Pandya and Vatsal Gupta and Agney S Talwarr and Tushar Kataria and Dan Roth and Vivek Gupta},
year={2025},
eprint={2407.10380},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2407.10380},
}



